2.4 Describing Quantitative Distributions
Consider the following exercise:
Your classmates write down the average time (in hours, to the nearest half-hour) they sleep per night and then create a simple dot plot of the data. Suppose the resulting Dot Plot looked like this:
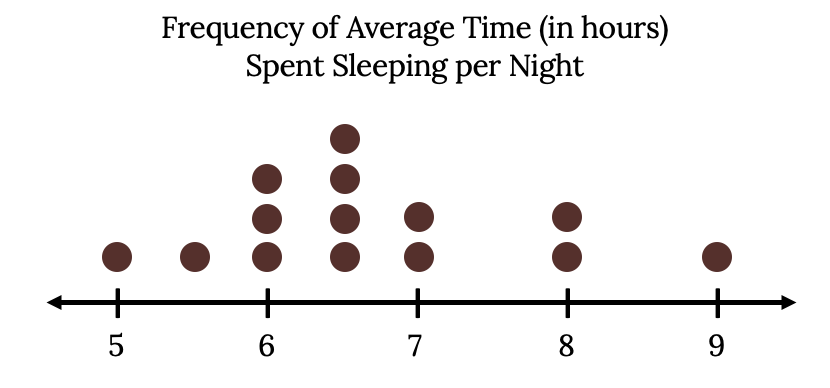
How would you interpret or explain this distribution? Where do your data appear to cluster? How might you interpret the clustering? If you did the same example in an English class with the same number of students, do you think the results would be the same? Why or why not?
The questions above ask you to analyze and interpret your data. It isn’t enough to just make graphs, we must be able to interpret it with a critical eye.
Key Aspects of Quantitative Data
When describing a Quantitative Distribution we want to at least note 4 things: The shape of the distribution, the presence of outliers, the center, and the spread. A helpful acronym to remember this is SOCS:
Shape is the main characteristic we can determine by looking at a graph. We are often able to identify potential outliers visually as well. Center and spread can be roughly gauged visually, but are more numerical calculations for those last two aspects will be discussed in the following sections.
Shape
Shape is the main characteristic we can determine by looking at a graph. The shape of a distribution is the first thing we should note since it will often dictate how to proceed with the rest of our analysis. We have already seen most of our graphical methods can give us on idea the shape of a distribution, but the best in most situations is a properly formatted histogram. Consider the following:
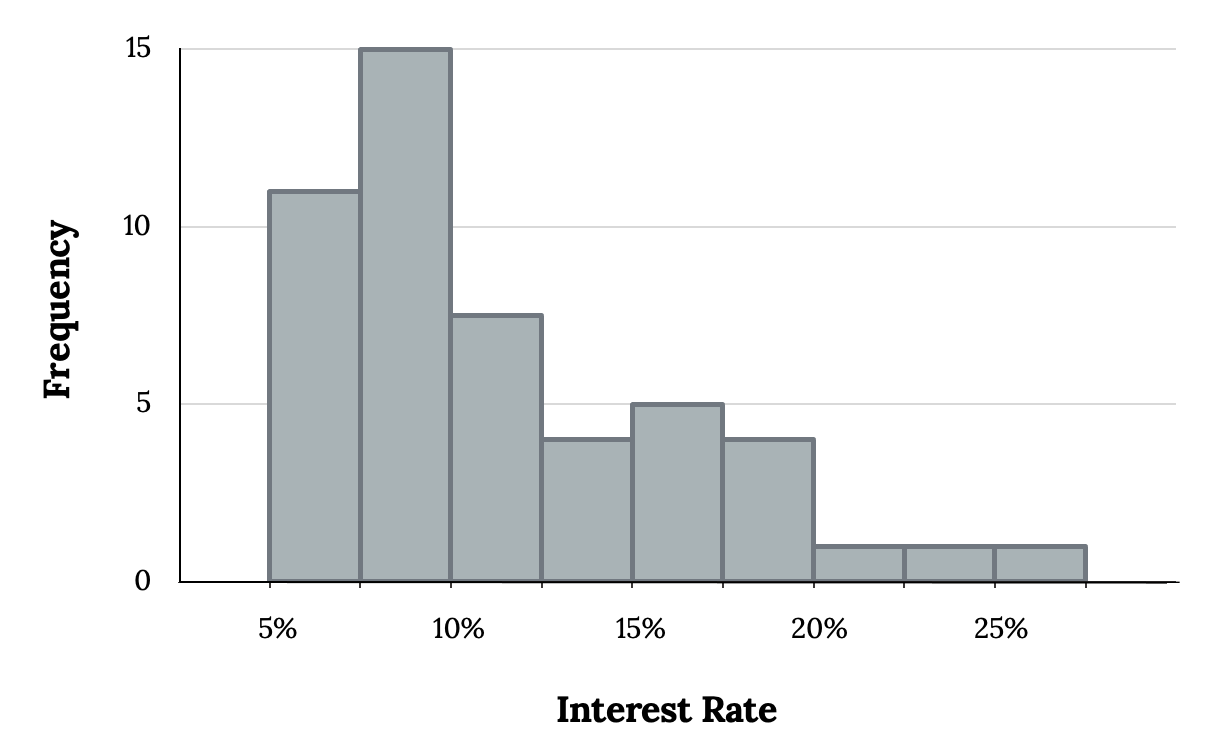
Histograms are especially convenient for understanding the shape of the data distribution. The figure above suggests that most loans have rates under 15%, while only a handful of loans have rates above 20%. When data trail off to the right in this way and has a longer right tail, the shape is said to be right skewed.
Data sets with the reverse characteristic – a long, thinner tail to the left – are said to be left skewed. We also say that such a distribution has a long left tail. Data sets that show roughly equal trailing off equally in both directions are called symmetric.
Modality
In addition to looking at whether a distribution is skewed or symmetric, histograms can be used to identify the modality of a distribution. A mode is represented by a prominent peak in the distribution. There is only one prominent peak in the histogram of loan amount. The definition of mode sometimes taught in math classes is the value with the most occurrences in the data set. However, for many real-world data sets, it is common to have no observations with the same value in a data set, making this definition impractical in data analysis. The figure below shows histograms that have one, two, or three prominent peaks.
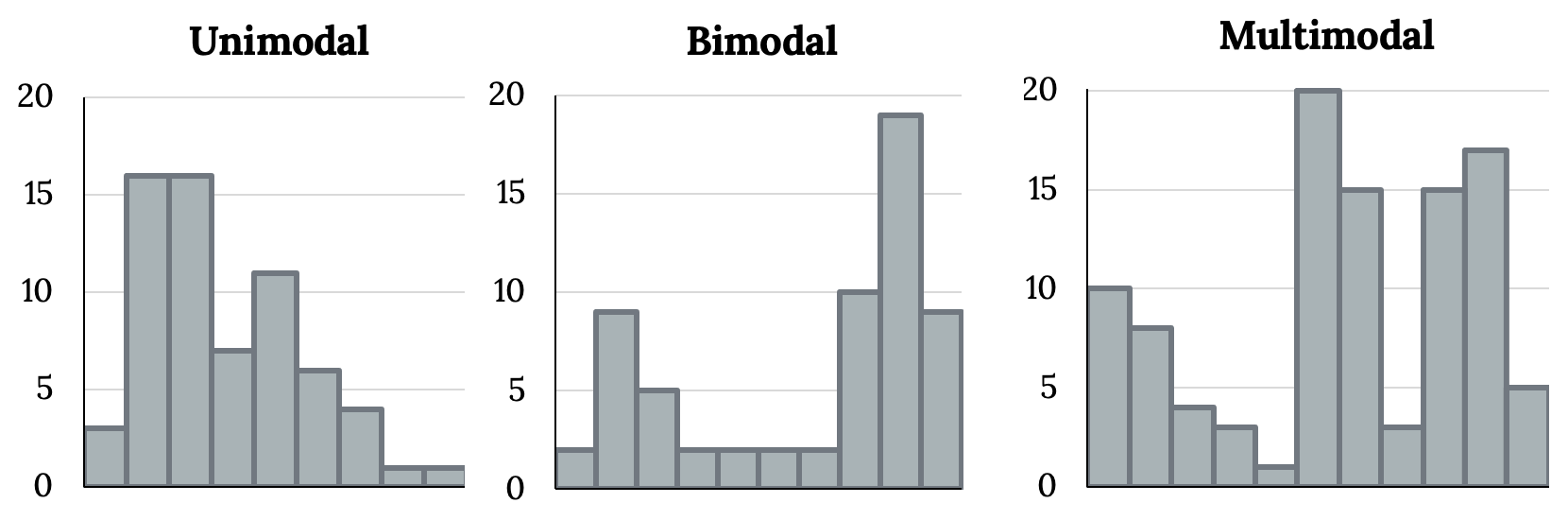
Such distributions are called unimodal, bimodal, and multimodal, respectively. Any distribution with more than 2 prominent peaks is called multimodal. Notice that there was one prominent peak in the unimodal distribution with a second less prominent peak that was not counted since it only differs from its neighboring bins by a few observations.
Looking for modes isn’t about finding a clear and correct answer about the number of modes in a distribution, which is why prominent is not rigorously defined in this book. The most important part of this examination is to better understand your data.
Outliers
Sometimes one or more data points that stick out visually. These extreme values could potentially be outliers. Sometimes they may be obvious to us as in the following histogram:
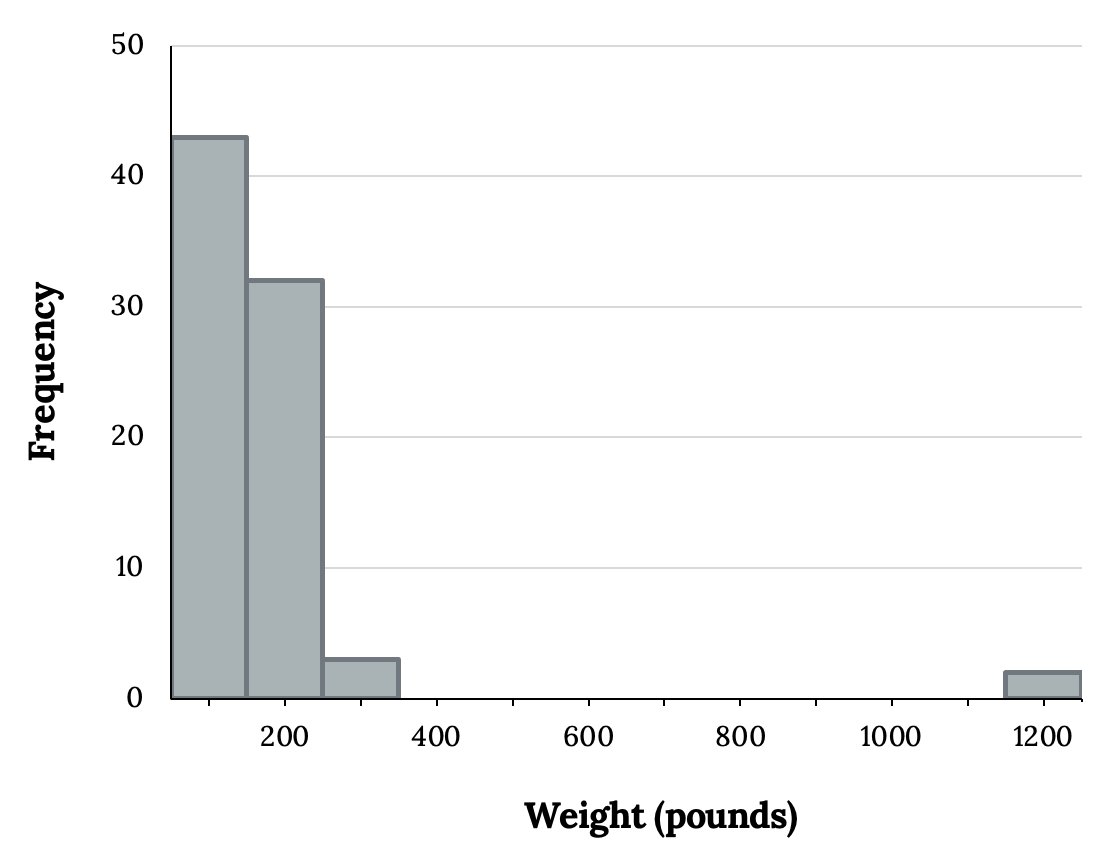
Or they may not be as obvious and might only show up upon careful examination of a dot plot or other methods. Examining data for outliers serves many useful purposes, including:
- Identifying skewness in the distribution.
- Identifying possible data collection or data entry errors.
- Providing insight into interesting properties of the data.
In subsequent sections we will see numerical methods to “officially” identify outliers and how to deal with them.
Center
We also want to make sure to describe a quantitative distribution’s “central tendency” or most “typical value”. We can simply estimate this visually but will see more robust and appropriate measures we can calculate in the future.
Spread
A rough measure of spread we can usually determine visually is the Range. Recall: Range = Maximum – Minimum. Again, we will see more robust and appropriate measures we can calculate in the future.
Example
Use the following graph to answer a-e.
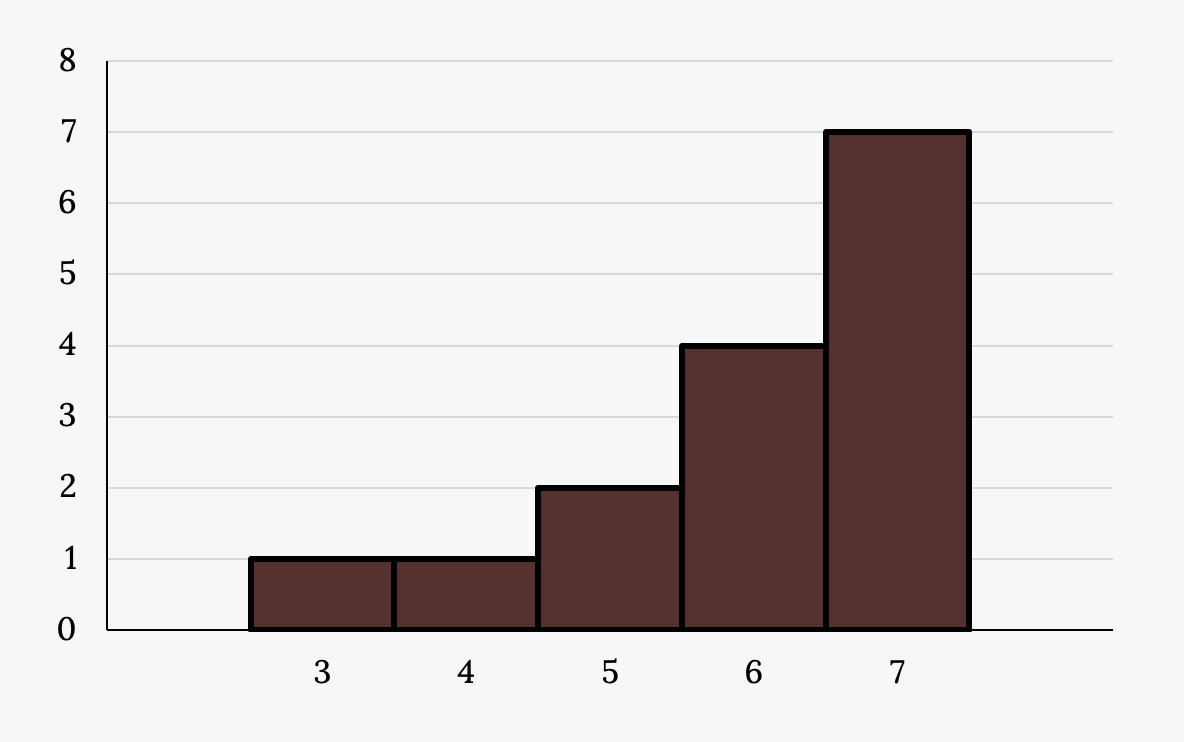
a. Describe the shape of this distribution.
b. Describe the modality of the distribution.
c. Do you see any apparent outliers?
d. What does the center appear to be?
Your turn!
Describe the shape of this distribution visually:
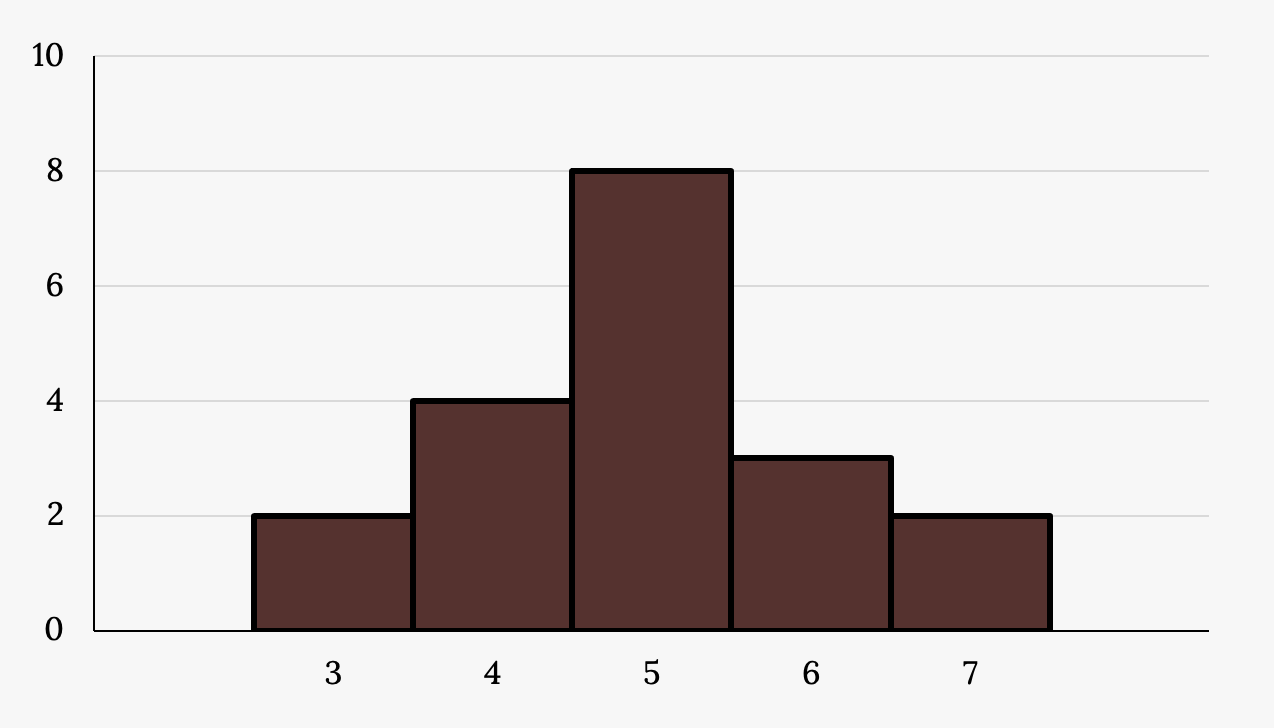
Image References
What a dataset looks like visually
An observation that stands out from the rest of the data significantly
The central tendency or most typical value of a dataset
The level of variability or dispersion of a dataset; also commonly known as variation/variability
How many peaks or clusters there appear to be in a quantitative distribution
