1.5 Sampling
Sampling
Gathering information about an entire population is often virtually impossible due to costs or other factors. Instead, we typically use a sample of the population which should have the same characteristics as the population it is representing. Statisticians use various methods of random sampling in an attempt to achieve this goal. This section will describe a few of the most common methods.
There are several different methods of random sampling. In each form, each member of a population initially has an equal chance of being selected for the sample. There are advantages and disadvantages to each sampling method.
Simple Random Sampling
The gold standard and maybe easiest method to describe is called a simple random sample (SRS). Any group of n individuals is equally likely to be chosen as any other group of n individuals if the simple random sampling technique is used. In other words, each sample of the same size has an equal chance of being selected.
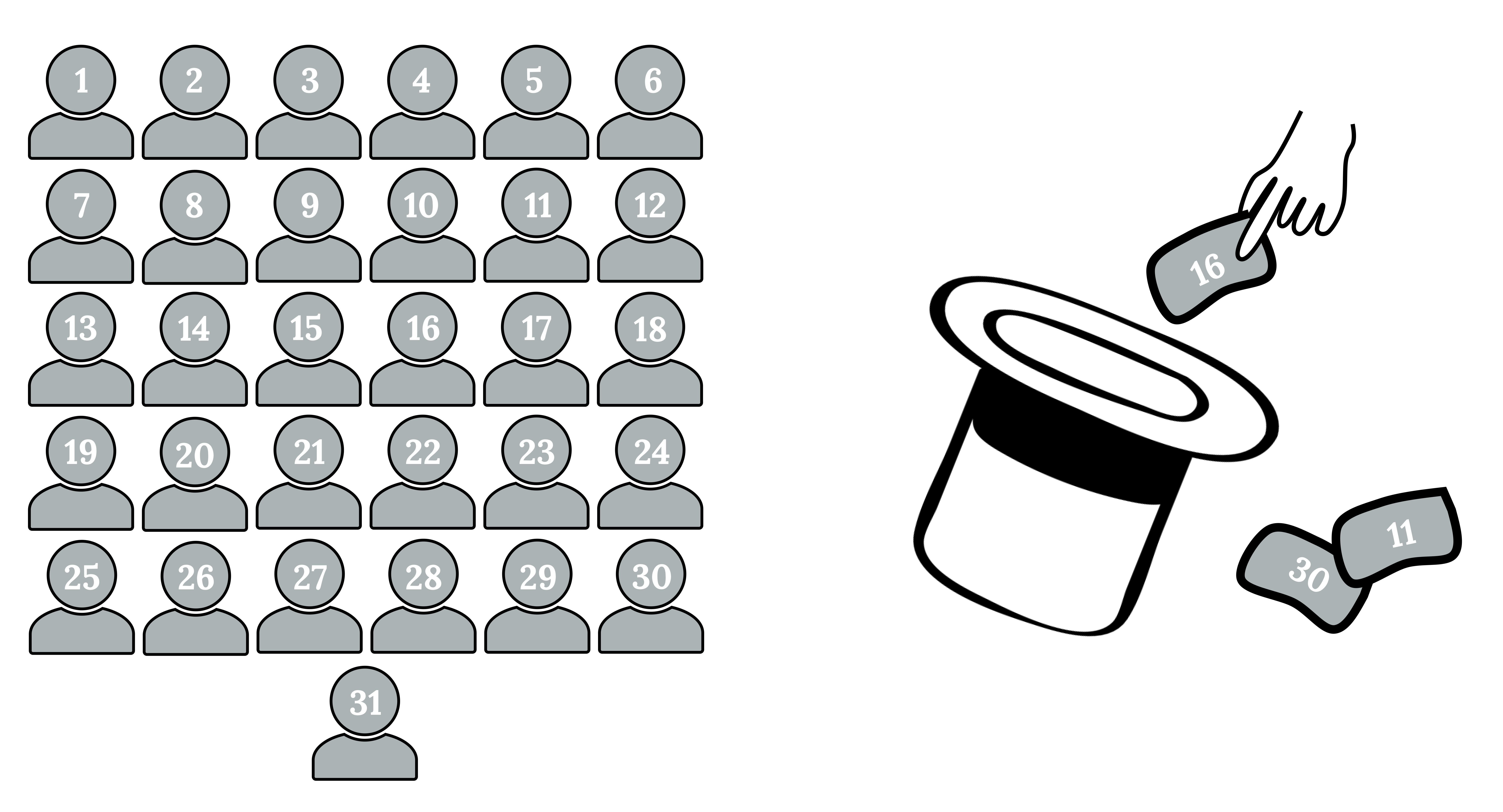
For example, suppose Lisa wants to form a four-person study group (herself and three other people) from her pre-calculus class, which has 31 members not including Lisa. To choose a simple random sample of size three from the other members of her class, Lisa could put all 31 names in a hat, shake the hat, close her eyes, and pick out three names.
A more technological approach is for Lisa to pair the last name of each class member with a two-digit number, as in the table below:
| ID | Name | ID | Name | ID | Name |
|---|---|---|---|---|---|
| 00 | Anselmo | 11 | King | 21 | Roquero |
| 01 | Bautista | 12 | Legeny | 22 | Roth |
| 02 | Bayani | 13 | Lundquist | 23 | Rowell |
| 03 | Cheng | 14 | Macierz | 24 | Salangsang |
| 04 | Cuarismo | 15 | Motogawa | 25 | Slade |
| 05 | Cuningham | 16 | Okimoto | 26 | Stratcher |
| 06 | Fontecha | 17 | Patel | 27 | Tallai |
| 07 | Hong | 18 | Price | 28 | Tran |
| 08 | Hoobler | 19 | Quizon | 29 | Wai |
| 09 | Jiao | 20 | Reyes | 30 | Wood |
| 10 | Khan |
Figure 1.8: Lisa’s class roster
Lisa can use a table of random numbers (found in many statistics books and mathematical handbooks), a calculator, or a computer to generate random numbers. For this example, suppose Lisa uses a calculator to generate the following random numbers:
0.94360, 0.99832, 0.14669, 0.51470, 0.40581, 0.73381, 0.04399
Lisa identifies multiple two-digit numbers in each of these random numbers (i.e., 0.94360 becomes 94, 43, 36, and 60). If any of these two-digit numbers corresponds with a name on her list, that student is chosen. She can generate more random numbers if necessary.
The random numbers 0.94360 and 0.99832 do not contain appropriate two-digit numbers. However, the third random number, 0.14669, contains 14, the fifth random number contains 05, and the seventh random number contains 04. The two-digit number 14 corresponds to Macierz, 05 corresponds to Cuningham, and 04 corresponds to Cuarismo. Besides herself, Lisa’s group will consist of Marcierz, Cuningham, and Cuarismo.
Other Sampling Techniques
In addition to simple random sampling, there are other forms of sampling that involve a chance process in getting the sample. Other well-known random sampling methods are:
To choose a stratified sample, identify a relevant similar characteristic of your population and divide people into groups, or strata, based on this characteristic. Then take a proportionate number from each stratum. For example, you could stratify (group) your college population by department and then choose a proportionate simple random sample from each department to get a stratified random sample. Note that there are six individuals in department one, 12 in department two, and nine in department three. If we wanted a total sample size of nine with equal representation from each department, we would randomly choose two individuals from department one, four from department two, and three from department three to make up the sample. Stratified random sampling is often used when we want to make sure our sample is representative of population demographics.
To choose a cluster sample, the population will need to be divided into predefined clusters or groups. Then, randomly select some of the clusters. All of the members from the selected clusters now make up your sample. For example, suppose your college has 5 departments pictured in different colors below. Each of these departments are the clusters. Number each department and choose two different numbers using simple random sampling. All members of the two chosen departments (grey and green) are the cluster sample.
To choose a systematic sample, randomly select a starting point and take every nth piece of data from a listing of the population. For example, suppose you have to do a phone survey. You have 60 contacts in your phone but can’t call all of them, so you decide on a sample size of 15. Number the population 1–60 and then use a simple random sample to pick a number that represents the first name in the sample. Then choose every fifth name thereafter until you have a total of 15 names. Systematic sampling is frequently chosen because it is a simple method.

Researchers may also choose to some a combination of these techniques, called multistage sampling.
Example
A study is conducted to determine the average tuition that Virginia Tech undergraduate students pay per semester. Each student in the following samples is asked how much tuition he or she paid for the fall semester. What is the type of sampling in each case?
Your Turn!
A local radio station has a fan base of 20,000 listeners. The station wants to know if its audience would prefer more music or more talk shows. Asking all 20,000 listeners is an almost impossible task. The station uses convenience sampling and surveys the first 200 people they meet at one of the station’s concert events. 24 people said they’d prefer more talk shows, and 176 people said they’d prefer more music. Do you think that this sample is representative of (or characteristic of) the entire 20,000 listener population?
Sampling and Replacement
True random sampling is done with replacement. That is, once a member is picked, that member goes back into the population and thus may be chosen more than once. However, for practical reasons, simple random sampling is done in most populations without replacement. Surveys are typically done without replacement, where a member of the population may be chosen only once. Most samples are taken from large populations, and the sample tends to be small in comparison to the population. Since this is the case, sampling without replacement is approximately the same as sampling with replacement because the chance of picking the same individual more than once with replacement is very low.
In a college population of 10,000 people, suppose you want to pick a sample of 1,000 randomly for a survey. For any particular sample of 1,000, if you are sampling with replacement,
- the chance of picking the first person is 1,000 out of 10,000 (0.1000);
- the chance of picking a different second person is 999 out of 10,000 (0.0999);
- the chance of picking the same person again is 1 out of 10,000 (very low).
If you are sampling without replacement,
- the chance of picking the first person for any particular sample is 1,000 out of 10,000 (0.1000);
- the chance of picking a different second person is 999 out of 9,999 (0.0999);
- you do not replace the first person before picking the next person.
Compare the fractions  and
and  . For accuracy, carry the decimal answers to four decimal places. To four decimal places, these numbers are equivalent (0.0999).
. For accuracy, carry the decimal answers to four decimal places. To four decimal places, these numbers are equivalent (0.0999).
Sampling without replacement instead of sampling with replacement becomes a mathematical issue only when the population is small. For example, if the population is 25 people, the sample is ten, and you are sampling with replacement for any particular sample, then the chance of picking the first person is 10 out of 25, and the chance of picking a different second person is 9 out of 25 (you replace the first person).
If you sample without replacement, then the chance of picking the first person is 10 out of 25, and then the chance of picking the second (different) person is 9 out of 24 (you do not replace the first person).
Compare the fractions  and
and  . To four decimal places, = 0.3600 and = 0.3750. To four decimal places, these numbers are not equivalent.
. To four decimal places, = 0.3600 and = 0.3750. To four decimal places, these numbers are not equivalent.
Bias in Samples
Sampling data should be done very carefully and collecting data carelessly can have devastating results. For example, surveys mailed to households and then returned may be very biased (they may favor a certain group). It is often best for the person conducting the survey to select the sample respondents.
When you analyze data, it is important to be aware of sampling errors and non-sampling errors. The actual process of sampling causes sampling errors. For example, the sample may not be large enough. Factors not related to the sampling process cause non-sampling errors. A defective counting device can cause a non-sampling error.
In reality, a sample will never be exactly representative of the population, so there will always be some sampling error. As a rule, the larger the sample, the smaller the sampling error.
In statistics, sampling bias is created when a sample is collected from a population and some members of the population are not as likely to be chosen as others. Remember, each member of the population should have an equally likely chance of being chosen. When sampling bias occurs, incorrect conclusions can be drawn about the population being studied.
Variation in Samples
As previously mentioned, two or more samples from the same population, taken randomly and having close to the same characteristics of the population, will likely be different from each other. Suppose Doreen and Jung both decide to study the average amount of time students at their college sleep each night. Doreen and Jung each take samples of 500 students. Doreen uses systematic sampling, and Jung uses cluster sampling. Doreen’s sample will be different from Jung’s sample. Even if Doreen and Jung used the same sampling method, the samples would surely be different. Neither would be wrong, however.
Think about why Doreen’s and Jung’s samples would be different.
If Doreen and Jung took larger samples (i.e., the number of data values is increased), their sample results (the average amount of time a student sleeps) might be closer to the actual population average. Even then, their samples would be, in all likelihood, different from each other. This idea of sampling variability cannot be stressed enough.
Size of a Sample
The size of a sample (often called the number of observations) is important. The examples you have seen in this book so far have been small. Samples of only a couple hundred observations (or even fewer) are sufficient for many purposes. In polling, samples consisting of 1,200 to 1,500 observations are considered large enough and good enough if the survey is random and well done. You will learn why when you study confidence intervals.
Be aware that even many large samples are biased. For example, call-in surveys are invariably biased because people choose to respond or not.
Critical Evaluation
We need to evaluate statistical studies critically and analyze them before accepting their results. Common problems include:
- Convenience sampling: A type of sampling that is non-random and involves using results that are readily available. For example, a computer software store conducts a marketing study by interviewing potential customers who happen to be in the store browsing through the available software. The results of convenience sampling may be very good in some cases and highly biased (favoring certain outcomes) in others.
- Problems with samples: A sample must be representative of the population. A sample that is not representative of the population is biased. Biased, unrepresentative samples give results that are inaccurate and not valid.
- Self-selected samples: Responses only by people who choose to respond, such as call-in surveys, are often unreliable.
- Sample size issues: Samples that are too small may be unreliable. Larger samples are better, if possible. In some situations, having small samples is unavoidable and can still be used to draw conclusions.
- Examples: Crash testing cars or medical testing for rare conditions
- Undue influence: Collecting data or asking questions in a way that influences the response
- Non-response or refusal of subject to participate: The collected responses may no longer be representative of the population. Often, people with strong positive or negative opinions may answer surveys, which can affect the results.
- Causality: A relationship between two variables does not mean that one causes the other to occur. They may be related (correlated) because of their connection through a different variable.
- Self-funded or self-interest studies: A study performed by a person or organization in order to support their claim. Is the study impartial? Read the study carefully to evaluate the work. Do not automatically assume that the study is good, but do not automatically assume the study is bad either. Evaluate it on its merits and the work done.
- Misleading use of data: Improperly displayed graphs, incomplete data, or lack of context
- Confounding: When the effects of multiple factors on a response cannot be separated. Confounding makes it difficult or impossible to draw valid conclusions about the effect of each factor.
Ethics
The widespread misuse and misrepresentation of statistical information often gives the field a bad name. Some say that “numbers don’t lie,” but the people who use numbers to support their claims often do.
A recent investigation into famous social psychologist Diederik Stapel has led to the retraction of his articles from some of the world’s top journals, including Journal of Experimental Social Psychology, Social Psychology, Basic and Applied Social Psychology, and the British Journal of Social Psychology, as well as the magazine Science. Diederik Stapel is a former professor at Tilburg University in the Netherlands. Over the past two years, an extensive investigation involving three universities where Stapel has worked concluded that the psychologist is guilty of fraud on a colossal scale. Falsified data taints over 55 papers he authored and ten PhD dissertations that he supervised.
Stapel did not deny that his deceit was driven by ambition. But it was more complicated than that, he told me. He insisted that he loved social psychology but had been frustrated by the messiness of experimental data, which rarely led to clear conclusions. His lifelong obsession with elegance and order, he said, led him to concoct sexy results that journals found attractive. “It was a quest for aesthetics, for beauty—instead of the truth,” he said. He described his behavior as an addiction that drove him to carry out acts of increasingly daring fraud, like a junkie seeking a bigger and better high.[1]
The committee investigating Stapel found him guilty of several misdeeds, including creating datasets that largely confirmed prior expectations, altering data in existing datasets, changing measuring instruments without reporting the change, and misrepresenting the number of experimental subjects.
Clearly, it is never acceptable to falsify data the way this researcher did. Sometimes, however, violations of ethics are not as easy to spot.
Researchers have a responsibility to verify that proper methods are being followed. The report describing the investigation of Stapel’s fraud states that “statistical flaws frequently revealed a lack of familiarity with elementary statistics.”[2] Many of Stapel’s co-authors should have spotted irregularities in his data. Unfortunately, they did not know very much about statistical analysis, and they simply trusted that he was collecting and reporting data properly.
Many types of statistical fraud are difficult to spot. Some researchers simply stop collecting data once they have just enough to prove what they had hoped to prove. They don’t want to take the chance that a more extensive study would complicate their lives by producing data contradicting their hypothesis.
Professional organizations like the American Statistical Association clearly define expectations for researchers. There are even laws in the federal code about the use of research data.
When a statistical study uses human participants, as in medical studies, both ethics and the law dictate that researchers are mindful of the safety of their research subjects. The U.S. Department of Health and Human Services oversees federal regulations of research studies with the aim of protecting participants. When a university or other research institution engages in research, it must ensure the safety of all human subjects. For this reason, research institutions establish oversight committees known as Institutional Review Boards (IRBs). All planned studies must be approved in advance by the IRB. Key protections that are mandated by law include the following:
- Risks to participants must be minimized and reasonable with respect to projected benefits.
- Participants must give informed consent. This means that the risks of participation must be clearly explained to the subjects of the study. Subjects must consent in writing, and researchers are required to keep documentation of their consent.
- Data collected from individuals must be guarded carefully to protect their privacy.
These ideas may seem fundamental, but they can be very difficult to verify in practice. Is removing a participant’s name from the data record sufficient to protect privacy? Perhaps the person’s identity could be discovered from the data that remains. What happens if the study does not proceed as planned and unanticipated risks arise? When is informed consent really necessary? Suppose your doctor wants a blood sample to check your cholesterol level. Once the sample has been tested, you expect the lab to dispose of the remaining blood. At that point, the blood becomes biological waste. Does a researcher have the right to use it in a study?
It is important that students of statistics take time to consider the ethical questions that arise in statistical studies. How prevalent is fraud in statistical studies? You might be surprised—and disappointed. There is a website (http://www.retractionwatch.com/) dedicated to cataloging retractions of study articles that have been proven fraudulent. A quick glance will show that the misuse of statistics is a bigger problem than most people realize.
Vigilance against fraud requires knowledge. Learning the basic theory of statistics will empower you to analyze statistical studies critically.
Example
A researcher is collecting data in a community. Describe the unethical behavior in each example and how it could impact the reliability of the resulting data. Explain how the problem should be corrected.
- She selects a block where she is comfortable walking because she knows many of the people living on the street.
- No one seems to be home at four houses on her route. She does not record the addresses and does not return at a later time to try to find residents at home.
- She skips four houses on her route because she is running late for an appointment. When she gets home, she fills in the forms by selecting random answers from other residents in the neighborhood.
Solution
- By selecting a convenient sample, the researcher is intentionally selecting a sample that could be biased. Claiming that this sample represents the community is misleading. The researcher needs to select areas in the community at random.
- Intentionally omitting relevant data will create bias in the sample. Suppose the researcher is gathering information about jobs and child care. By ignoring people who are not home, she may be missing data from working families that are relevant to her study. She needs to make every effort to interview all members of the target sample.
- It is never acceptable to fake data. Even though the responses she uses are “real” responses provided by other participants, the duplication is fraudulent and can create bias in the data. She needs to work diligently to interview everyone on her route.
Your Turn!
Describe the unethical behavior, if any, in each example and how it could impact the reliability of the resulting data. Explain how the problem should be corrected.
A study is commissioned to determine the favorite brand of fruit juice among teens in California.
- The survey is commissioned by the seller of a popular brand of apple juice.
- There are only two types of juice included in the study: apple juice and cranberry juice.
- Researchers allow participants to see the brand of juice as each sample is poured for a taste test.
- Twenty-five percent of participants prefer Brand X, 33% prefer Brand Y, and 42% have no preference between the two brands. Brand X references the study in a commercial, saying “Most teens like Brand X as much as or more than Brand Y.
Additional Resources
Figure References
Figure 1.7: Kindred Grey (2024). Simple random sample. CC BY-SA 4.0.
Figure 1.9: Kindred Grey (2024). Stratified sample. CC BY-SA 4.0.
Figure 1.10: Kindred Grey (2024). Cluster sample. CC BY-SA 4.0.
Figure 1.11: Kindred Grey (2024). Systematic sample. CC BY-SA 4.0.
Figure Descriptions
Figure 1.7: 31 people. Put numbers one through 31 into a hat and draw out three numbers.
Figure 1.9: Three groups. All grouped by similar characteristics. Group one has six people. Put six numbers in a hat and draw two. Group two has 12 people. Put 12 numbers in a hat and draw four. Group three has nine people. Put nine numbers in a hat and draw three.
Figure 1.10: Five groups with varying numbers of people all grouped by a similar characteristic. Put five numbers in a hat and draw two. Use all the people in both of these groups as your sample size.
Figure 1.11: 60 people. Put 60 numbers in a hat and pull out one random number. That is the first person you’ll sample. If you want to have a sample size of 15, then sample every four people until you reach the number you chose from the hat. It’s okay to loop back to the first person.
- Yudhijit Bhattacharjee, “The Mind of a Con Man,” Magazine, New York Times, April 26, 2013. Available online at: http://www.nytimes.com/2013/04/28/magazine/diederik-stapels-audacious-academic-fraud.html?src=dayp&_r=2& (accessed May 1, 2013). ↵
- “Flawed Science: The Fraudulent Research Practices of Social Psychologist Diederik Stapel,” Tillburg University, November 28, 2012, http://www.tilburguniversity.edu/upload/064a10cd-bce5-4385-b9ff-05b840caeae6_120695_Rapp_nov_2012_UK_web.pdf (accessed May 1, 2013). ↵
A subset of the population studied
Each member of the population is equally likely to be chosen for a sample of a given sample size and each sample is equally likely to be chosen
Dividing a population into groups (strata) and then using simple random sampling to identify a proportionate number of individuals from each
A method of sampling where the population has already sorted itself into groups (clusters), and researchers randomly select a cluster and use every individual in the chosen cluster as the sample
Using some sort of pattern or probability-based method for choosing your sample
Bias resulting from all members of the population not being equally likely to be selected
The idea that samples from the same population can yield different results
Selecting individuals that are easily accessible and may result in biased data
